HDFS Tutorial: The Only Guide You’ll Ever Need
I think you guys will agree with me when I say:
The coming time is of BIG DATA & ANALYTICS
You are here as you want to learn HDFS and you are looking for HDFS Tutorial. One thing I assure you is when you will leave this HDFS Tutorial site, you will have a fair understanding of HDFS and many other components of Hadoop and working.
 Forget everything that you have heard so far like HDFS is a big thing, Hadoop is so hard etc.…After going through this blog and HDFS tutorial, you will feel like a simple ABC as I also have undergone through the same thing and this is the reason behind starting this HDFS Tutorial.
Forget everything that you have heard so far like HDFS is a big thing, Hadoop is so hard etc.…After going through this blog and HDFS tutorial, you will feel like a simple ABC as I also have undergone through the same thing and this is the reason behind starting this HDFS Tutorial.
This is exactly the same guide what I follow and I have ensured that if you heard about Hadoop and HDFS for the first time also, you will get to know what’s going on here.
To make this guide simple, I am going to divide this HDFS Tutorial into a different section and we will go one by one.
CHAPTER 1: What is Hadoop- An Introduction
CHAPTER 2: An Overview with HDFS
CHAPTER 3: Why we need HDFS- Exact Reasons
CHAPTER 4: Important Hadoop Terminology
CHAPTER 5: HDFS Architecture
CHAPTER 6: Working of HDFS
CHAPTER 7: Various File Format Hadoop Supports
CHAPTER 8: HDFS UNIX Commands
CHAPTER 9: Wrapping it UP
So, as you can see, I have categorized this HDFS Tutorial into the above 09 chapters and we will go through each in details with examples, resources and videos as required.
Well, so welcome to the world of BIG DATA and Hadoop. Believe me, the coming time is of data and you should be well prepared to handle that.
Due to the growing technologies, things have become easy compared to what we had. Social media is playing a very important role and people are loving it.
But at the same time, with the advent of these social media sites, e-commerce stores, and other websites, the amount of data generated by them is also increasing rapidly.
Here is a trend of social media data (as per 2014)
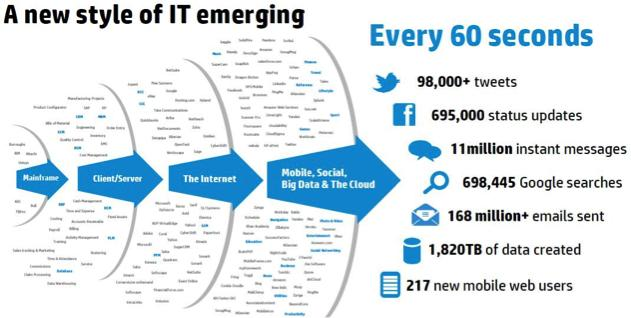
The amount of data produced by us from the beginning of time till 2003 was 5 billion gigabytes. If you pile up the data in the form of disks it may fill an entire football field. The same amount was created in every two days in 2011 and in every ten minutes in 2013.
So you can think of how fast the data are getting generated and the volume of the data. These data are so huge that a traditional database is unable to handle and operate it.
And the main thing is it is getting folded multiple times each year. A recent survey by Oracle has estimated that by 2020, we will have over 40 ZB of data.
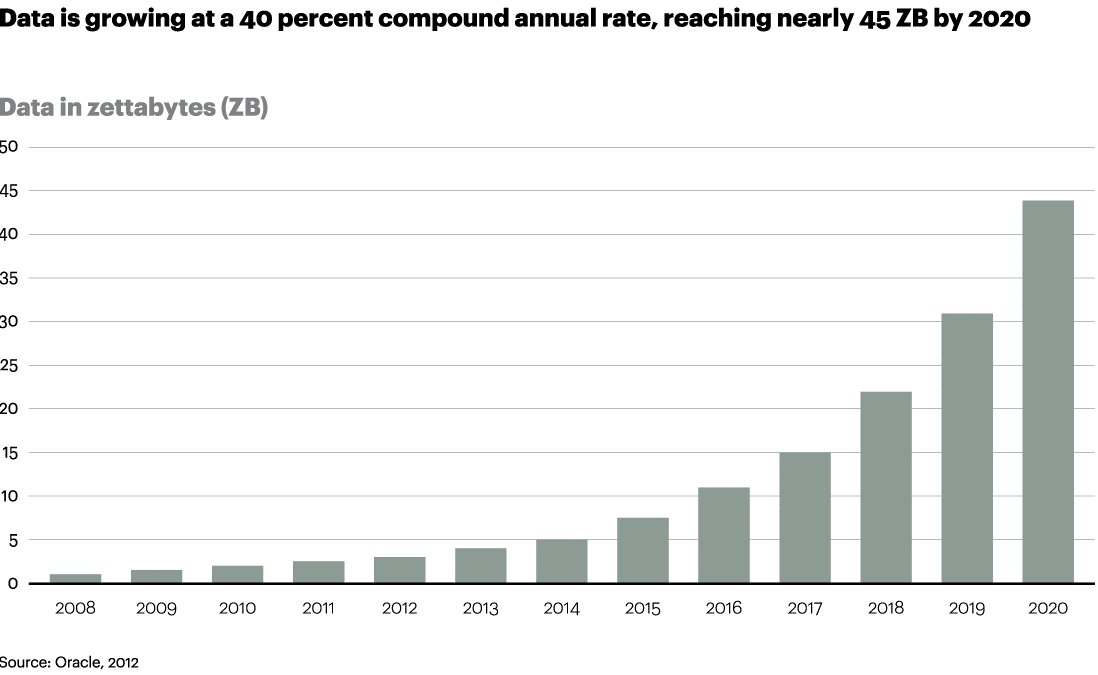
Note: 1 ZB=1e+12 GB
Such kind of data are called Big Data and as the traditional RDBMS is unable to handle such huge data and so we needed a special technology which can manage these big data and hence Hadoop came into existence.
What is Hadoop?
Hadoop is a free, Java-based programming framework that supports the processing of large data sets in a distributed computing environment. It is part of the Apache project sponsored by the Apache Software Foundation.

There are a number of ecosystems in Hadoop which are used for different purpose and collectively all these serves the purpose to manage the big data.
So by now you must be thinking that what are the sources of such a huge data…right?
Sources of Big Data
Well, there are a number of different sources of huge data and collectively those becomes big data. I am going to list few sectors through which such huge data mainly comes-
• Social Media Data: From Facebook, Twitter, and Google+ etc.
• Stock Exchange Data: Information about the buy and sell done by customers in stock exchange
• Power Grid Data: Power grid holds information consumed by particular nodes
• Transport Data
• Search Engine Data
• Sentiment Data: Data received from the comments/shares done on some blog posts or news
• Sensor Data: Barcode reader data

And much more…
All these data can be divided into the following 3 sections–
Big Data Classification
The data those are getting generated from all the above sources can be divided into following three categories-
2. Semi-structured Data- JSON, XML data
3. Unstructured data- Word files, Images, Text, PDF etc.
Challenges of Big Data
When initially this huge amount of data started coming, some challenges started companies started thinking and working to solve those. Here are some of the challenges those started coming in initial days-
• Curation
• Storage
• Searching
• Sharing
• Transfer
• Analysis
• Presentation
Hadoop solved these issues later with the help of their ecosystems.
History of Hadoop
Google started working on the above challenges and come up with the solution called MapReduce which was working on the concept of splitting the big files into small packets and processing those in parallel and finally collecting the output.
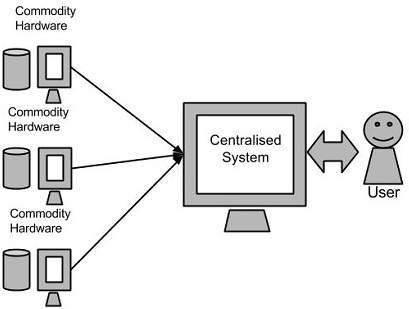
Then back in 2005, Doug Cutting, Mike Cafarella, and the team took the solution provided by Google and started working on some permanent and standard solution to handle big data and come up with the framework called HADOOP.
Now Apache Hadoop is a registered trademark of the Apache Software Foundation.
There is another interesting story behind naming it Hadoop and the logo of an elephant. At that time Doug’s son was playing with a toy which was an elephant and his son was calling that toy elephant Hadoop and so he named this framework Hadoop and kept the same elephant logo.
Hadoop Architecture
I am not going to explain Hadoop architecture in details here and am just providing you some background as how we reached and needed HDFS.
Here is a simple Hadoop architecture-
Hadoop architecture has mainly 4 component as follows-
2. HDFS- Provides access to application data
3. Yarn- to manage cluster resources and for job scheduling
4. MapReduce- for parallel processing of data sets
This concludes the first chapter “WHAT IS HADOOP?”. I am sure you now have a clear understanding of Hadoop basics.
If you liked this page, please share so that others will have a clear understanding of Hadoop and Big Data and head over to the next chapter to start with HDFS Tutorial.