We have come to the half way of HDFS Tutorial and this HDFS Architecture is the 5th chapter of our HDFS Tutorial Series.This and the next to it will be an interesting chapter to read and most important as well. Concentrate on this and you will never face issue with understanding like how the system exactly works.
We have already talked about the Block, DataNode, and NameNode…right? Let’s see how these are being actually used and its operation.
As I have told you the file that we want to process gets divided into blocks and also I have told you that these DataNodes are commodity hardware then what in the case of failures?
Valid question…
Well, Hadoop is highly fault tolerant system. What we do here is, we replicate the blocks. Suppose you have 3 blocks then it will be replicated and stored so that in the case of any failure (though we have secondary NameNode), the data should not be lost.
By default, the replication factor in Hadoop is 3
That means all the blocks will be replicated 3 times. For example, if you 3 blocks then it will be replicated 3 times and so in total you have 9 blocks.
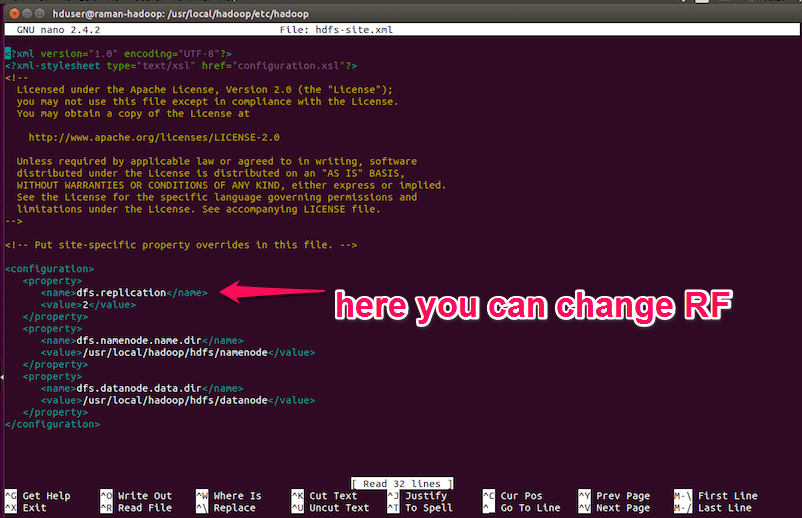
You can increase or decrease the replication factor and depend on the number of DataNode you have, select the replication factor. This can be done by changing in hdfs-site.XML file as shown below-
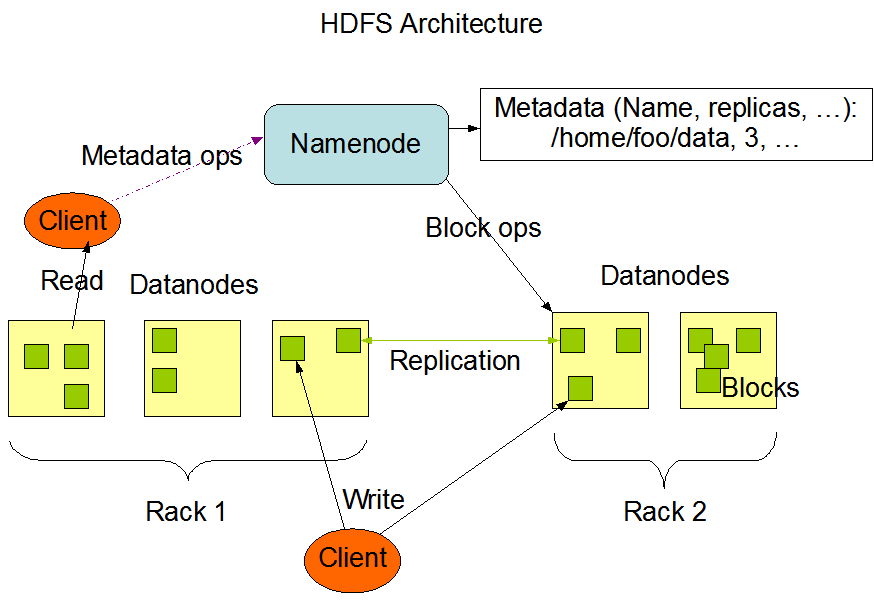
Here is a simple and self-explaining image of HDFS Architecture-
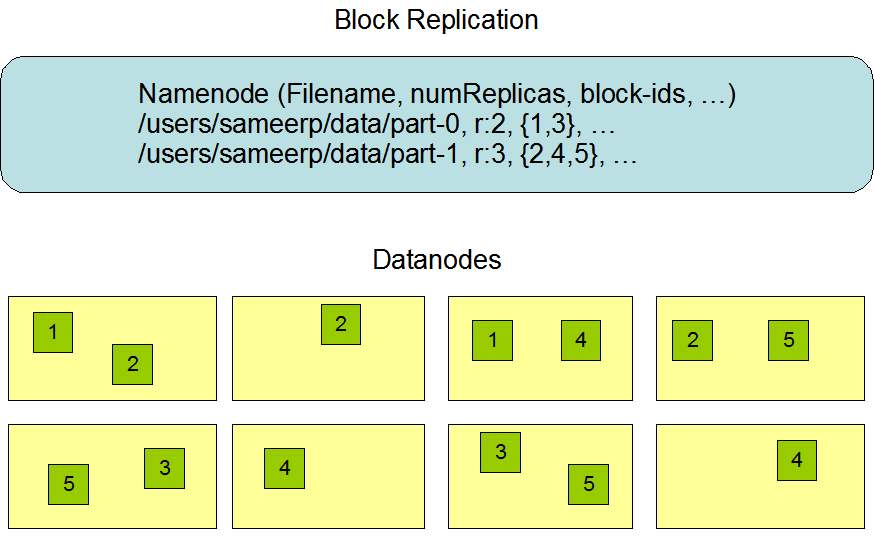
So suppose we have 5 blocks, the below can be an ideal distribution-

Previous Chapter: Hadoop TerminologyCHAPTER 6: HDFS File Processing