Chapter 2: Sqoop Architecture
In our last chapter, I talked that Sqoop is mainly used to import data from relational databases to Hadoop and export data from Hadoop to relational database.
Here I will show you how exactly this is being done by using a simple Sqoop architecture. Below is a simple Sqoop architecture for your reference-
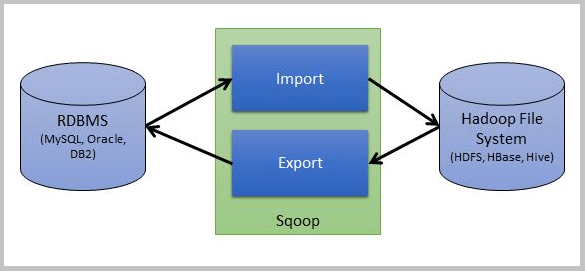
As you can see in above diagram, there is one source which is RDBMS like MySQL and other is a destination like HBase or HDFS etc. and Sqoop performs the operation to perform import and export.
I will discuss more how to import and export in our next chapter.
When Sqoop starts functioning, only mapper job will run and reducer is not required. Here is a detailed view of Sqoop architecture with mapper-
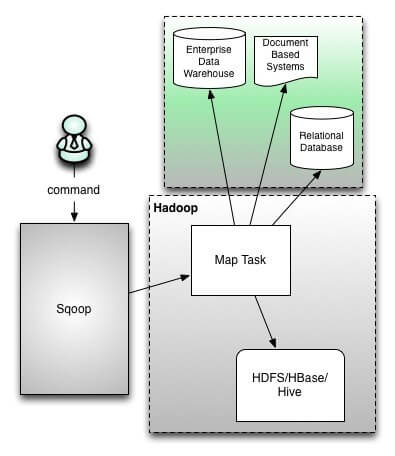
Sqoop provides command line interface to the end users and can also be accessed using Java API. Here only Map phase will run and reduce is not required because the complete import and export process doesn’t require any aggregation and so there is no need for reducers in Sqoop.
There are mainly a couple of functions those Sqoop mainly do-
- Import and
- Export
Let me explain both a bit here and in detail in the coming chapters.
Sqoop Import
The Sqoop import tool will import each table of the RDBMS in Hadoop and each row of the table will be considered as a record in the HDFS.
All records are stored as text data in text files or as binary data in Avro and Sequence files.
Sqoop Export
The Sqoop export tool will export Hadoop files back to RDBMS tables. The records in the HDFS files will be the rows of a table.
Those are read and parsed into a set of records and delimited with a user-specified delimiter.