HDFS overview is the 2nd episode of HDFS Tutorial series. HDFS is the short form of Hadoop Distributed File system and works as a storage of data for Hadoop framework.
It is a very important component in Hadoop ecosystem and the base also. According to The Apache Software Foundation, the primary objective of HDFS is to store data reliably even in the presence of failures including NameNode failures, DataNode failures, and network partitions. The NameNode is a single point of failure for the HDFS cluster and a DataNode stores data in the Hadoop file management system.
HDFS mainly works on a master-slave architecture where one device (master) controls one or more devices.
I will talk more about master and slave in later chapters. We will also discuss the NameNode (NN) and DataNode (DN) then.
HDFS provides high high-performance access to data across Hadoop clusters. One of the other significant benefits of HDFS is, it just need commodity hardware.
So if you are thinking what is commodity hardware then here is a small note for you-
Commodity hardware is low-cost hardware. It is same which we use on our laptop or desktop where we get a laptop with 1TB in just $400-600.
But at the same time if you will go with the high-class hardware used in data centers then just for a TB of hard drive you may have to pay around $10k-$20k.
This is the difference between commodity hardware and high-class hardware. Let me talk more about a different kind of device here-
 But at the same time if you are using the commodity hardware is less fault tolerance and there are a high chance of being corrupted or may get impacted due to the virus and so organizations prefer high-class hardware.i0.
But at the same time if you are using the commodity hardware is less fault tolerance and there are a high chance of being corrupted or may get impacted due to the virus and so organizations prefer high-class hardware.i0.
To resolve this issue, HDFS came and helped.
Evolution of HDFS
Once Google gave the concept of GFS (Google file system) and MapReduce on paper (yes not implemented yet), another search engine giant Yahoo, took the idea and started working. The main idea behind GFS was to distribute the large files into small files and then process and to process they introduced MapReduce which will process the file parallels.
Eg. Let us consider one example where one house is to be built. One person is working on it and is expecting to be completed in a year.
What if we will introduce 12 people to do that job? A number of days will be less…right? Can they complete in a month or max 2…agree?
Means they will work parallel and so the task will get completed fast, and at the end, the work they will do will be collectively known as a home…right?
The same is the HDFS and MapReduce working.
So Yahoo took the idea from Google’s paper and started working and came up with a working model known as HDFS (Hadoop distributed file system).
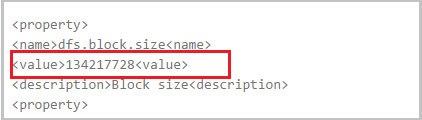
Here large files get divided into small blocks and then getting processed. These block size can be anywhere between 64-128 MB.
Previous Chapter: What is Hadoop?CHAPTER 3: Why we need HDFS