If you’ve done sqoop incremental import, you must have seen we need to provide the last incremented value each time we do sqoop incremental import.
But in normal working we don’t run such sqoop incremental import daily or when needed. We basically automate sqoop incremental import work so that automatically it will import the incremented values.
In this tutorial, we are going to see how to automate sqoop incremental import. If you’re new to sqoop, you may follow our free sqoop tutorial guide.
How to automate sqoop incremental import job?
In sqoop incremental import, the newly added record of the RDBMS table will be added to the file those have already been imported to HDFS.
So, let’s start and see how to automate sqoop incremental import.
I. Let’s first create a table in MySQL with the name customer-
mysql> create table customer(id int primary key, name varchar(500), age int, salary varchar(100));
Note: You can use the command-
mysql -u root -p
to go into the MySQL shell inside Hadoop. It will ask you the password and you can use cloudera as password if using CDH. Else, try password as hadoop.
II. Add some record in this table so that we have something to run sqoop import operation.
mysql> create table hdfs_cust(id int primary key, name varchar(500), age int, salary varchar(100));

Insert data into MySQL Table
Like this, I have inserted a few records and my table is looking like below-
 III. Now simply import this MySQL table “customer” to Hadoop using simple Sqoop import function as below-
III. Now simply import this MySQL table “customer” to Hadoop using simple Sqoop import function as below-
$sqoop import --connect jdbc:mysql://localhost/sqoop --username root --password cloudera --table customer -m1 --target-dir /user/cloudera/increment_files/

Sqoop Import Command
Once this will be executed, you’ll see the progress and at last, you’ll get the summary something like below-
 This shows that 10 records (which we had in MySQL table customer) have been transferred.
This shows that 10 records (which we had in MySQL table customer) have been transferred.
IV. You can verify the records in the HDFS location we specified in the Sqoop import function
hadoop fs -cat /user/cloudera/increment_files/part-m-00000
 So, we have successfully imported the MySQL data in Hadoop using Sqoop. Now we will implement the Sqoop incremental import. We will select Id as the incremented column.
So, we have successfully imported the MySQL data in Hadoop using Sqoop. Now we will implement the Sqoop incremental import. We will select Id as the incremented column.
V. For that add one more record in the MySQL table customer
 VI. Now we have an additional record with id=11 which needed to be imported in the Hadoop file. For that we will use the sqoop incremental import as shown below-
VI. Now we have an additional record with id=11 which needed to be imported in the Hadoop file. For that we will use the sqoop incremental import as shown below-
sqoop import --connect jdbc:mysql://localhost/sqoop --username root --password cloudera --table customer -m1 --target-dir /user/cloudera/increment_files/ --incremental append --check-column id --last-value 10
 Once done, you’ll get summary something like below-
Once done, you’ll get summary something like below-
 You can again check the data using simple cat command in the same file as shown below-
You can again check the data using simple cat command in the same file as shown below-
 But as you can see we had to provide the last incremented value as 10 here and then the system imported all values after 10. But we won’t be able to do it manually.
But as you can see we had to provide the last incremented value as 10 here and then the system imported all values after 10. But we won’t be able to do it manually.
And so, we will automate sqoop incremental job here. To do that, we need to create a sqoop job as shown below.
VII. Simply we will create a sqoop job with the name job_inc3 which will basically save our sqoop incremental import command as shown below-
sqoop job --create job_inc1 -- import --connect jdbc:mysql://localhost/sqoop --username root --password cloudera --table customer --target-dir /user/cloudera/increment_files/ --incremental append --check-column id --last-value 0
 This will simply create a job for sqoop incremental import. Please note here we have used last value as 0.
This will simply create a job for sqoop incremental import. Please note here we have used last value as 0.
You can check the created job as below-
 Now again add a new record to your MySQL table to test whether this automation works or not. And so, I am going to add a new record with the id=12.
Now again add a new record to your MySQL table to test whether this automation works or not. And so, I am going to add a new record with the id=12.
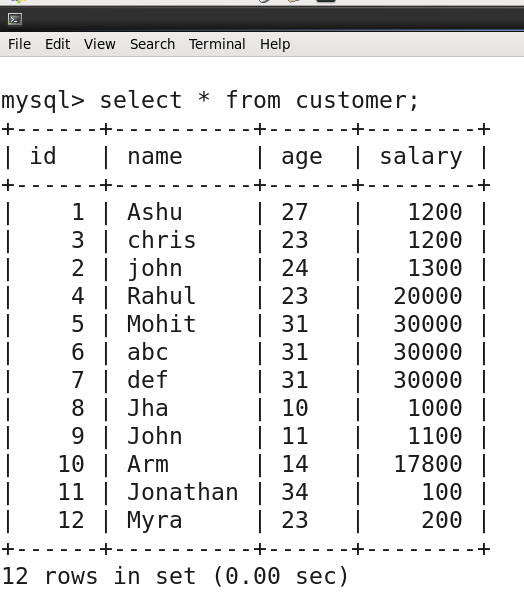 Now all you have to do is, simply execute the created sqoop incremental job as shown below-
Now all you have to do is, simply execute the created sqoop incremental job as shown below-
sqoop job --exec job_inc3
Once the above statement will be executed, you will get the summary like below. Please note if id is not primary key then you should use a number of mapper as 1 in the sqoop incremental job that we created above.
 Again, you can simply do the cat on the file and check whether the newly added record has been imported or not-
Again, you can simply do the cat on the file and check whether the newly added record has been imported or not-
 So, the newly added record in MySQL table has been successfully imported in Hadoop now. Like this, you can schedule the sqoop incremental job “job_inc3” we created and get rid of adding last value every time.
So, the newly added record in MySQL table has been successfully imported in Hadoop now. Like this, you can schedule the sqoop incremental job “job_inc3” we created and get rid of adding last value every time.
Conclusion
This was all about how to automate sqoop incremental import. We did that using a sqoop incremental job. The same can also be achieved by Oozie as well which we will talk in some other blog post. Please try this and let us know if you will find any issue.


I created a job using above mentioned syntax, but while executing it, I am getting INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
–table or –query is required for import. (Or use sqoop import-all-tables.),
and nothing happens after that