Hadoop is now a well-established and widely used technology for analyzing data on a large scale. All AI and data startups are helping the companies by providing the analytics to boost sell online.

From a small server log to large log files of big e-commerce companies, all are making use of Hadoop to store and analyze data in real time.
The modern Hadoop system not only provides a reliable distributed aggregation system that seamlessly delivers data parallelism but also helps you to get great analytics on that and further helps to take business recommendations.
But when a new company starts working on Hadoop, the very first few things one need to know is Hadoop cluster. Usually, the company hires big data architect who designs the Hadoop cluster.
So, this article is for the Hadoop architect or for those who want to learn how to design a Hadoop cluster. Here we will discuss, how to design a highly available and fault-tolerant Hadoop cluster.
[box type=”info”] Note: You can also use our service to get started with Hadoop. Our expert team will design and setup the Hadoop cluster for your organization.[/box]How to Design Hadoop Cluster: Detailed & Working Steps
Before moving ahead, let’s first see the core component of a Hadoop cluster-
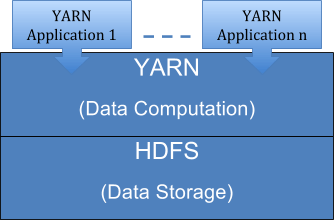
The yarn is for resource allocation and is also known as MapReduce 2.0 which is a part of Hadoop 2.0. Now we will deal with each component separately and see what all points we should take care while designing fault tolerant and highly available Hadoop cluster.
HDFS Cluster
HDFS cluster is mainly comprised of a NameNode and multiple datanodes in master-slave fashion. If you are new to HDFS, we recommend you to go through HDFS Tutorial to understand in details.
NameNode is like the monitor of the HDFS cluster which supervises the operation and stores the details about the datanodes and operations.
It is a single point failover and so usually a NameNode will be a high-end hardware compared to commodity hardware for DataNodes.
The NameNode stores block and DataNode information in local drives as the namespace image and the edit log.
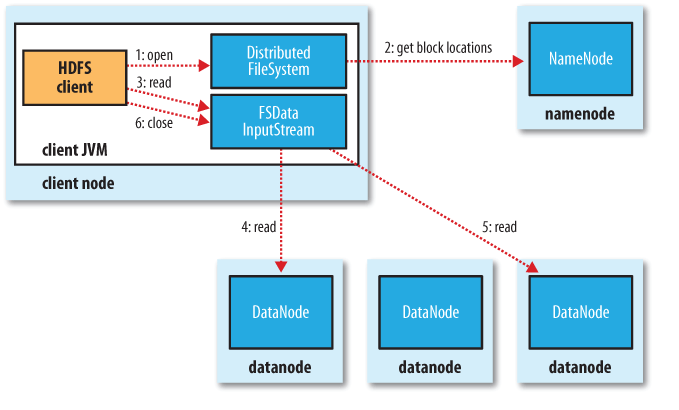
Now whenever the client sends a file, it is being received by NameNode and gets divided into the blocks which will be received by the datanodes. Check HDFS working to know about the working of HDFS.
YARN Architecture
The yarn is nothing but the MapReduce 2.0 in Hadoop 2 which separates resource management from application management. It also helps in separating the job scheduling and monitoring from resource management.
The Yarn architecture mainly comprise of ResourceManager, ApplicationMaster, and NodeManager.
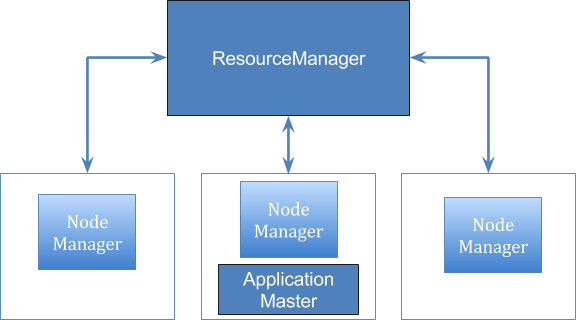
Here ApplicationMaster is managing the different users per application. There is one ApplicationMaster per application.
There is a JobHistoryServer which tracks these applications and mark their completion. In Yarn, NodeManager plays the same role which Task Tracker used to play in Hadoop 1. It tracks the task those run on each node.
These were the components you will need while designing a Hadoop cluster. Now we will have to think about the features for which Hadoop is meant to be.
Below are the features, a Hadoop cluster should have-
• High Availability – Cluster should not fail ever
• Security – Hadoop cluster should be designed in a way to incorporate all the security features
• Scale Out – maximize (network IO) performance and minimize physical size.
• Hadoop on Virtual Machines – to increase the utilization and reliability
Let’s discuss these features one by one and how to achieve these while designing a Hadoop cluster which will highly fault tolerant and will provide high availability.
High Availability
High Availability means the cluster should never fail. If it is going down also we should have something which will take the process up automatically.
Hadoop 2 provides a configuration where we have a couple of NameNode. One will be active and another in standby mode and so it avoids the single point failover.
So whenever there will be any failover, the standby node will automatically take up and will bring down the active node. The standby NameNode takes up very quickly as both the NameNodes share the edit log and the DataNodes report back to both the active and standby NameNodes. Also, ResourceManager in YARN can support high availability.
Security
Whenever we talk about the security while designing a Hadoop cluster, we mainly deal with the following four aspects of security-
• Authentication
• Authorization
• Audit
• Data Protection
Let’s see how to incorporate these features while designing a Hadoop cluster-
Authentication
The most common authentication involves in apache Hadoop is Kerberos. This is same as the other server where the authentication can be from user to service or service to the user (HTTP/HTTPS).
Authorization
For authorization, it already has Unix-like file permissions and different components like MR jobs have their own permission settings.
Audit
Audit or accountability is already built in Hadoop in the form of logs. There are history logs for JobTracker, JobHistoryServer, and ResourceManager and audit log for NameNode which take care of the logs of opening, closing etc.
Data Protection
Data protection means both- data protection in rest and data protection in motion. Data protection in rest is getting done by the encryption methods of operating systems or any hardware level of encryption.
For data in motion, we have to take different scenarios as explained below-
• For client interaction over RPC: SASL (Simple Authentication and Security Layer) protocol can be enabled by setting the ‘hadoop.rpc.protection=privacy’ in core-site.xml.
• HTTP over SSL simply setting ‘dfs.https.enable=true’ and then enabling two-way SSL by ‘dfs.client.https.need-auth=true’ in hdfs-site.xml
• For MapReduce Shuffle, SSL can be enabled by setting ‘mapreduce.shuffle.ssl.enabled=true’ in mapred-site.xml.
Scale out
Although Hadoop mainly uses commodity hardware which is of low cost but still data traffic with Hadoop is always a big deal.
Even if you have a medium size cluster, there is a lot of replication traffic and also the movement of data between Mappers and Reducers. SO you should choose your hardware and the size very carefully. Use this formula to calculate HDFS node storage and number of datanodes required.
Use the hardware which can provide a low latency (almost 0) and high bandwidth interconnect required.
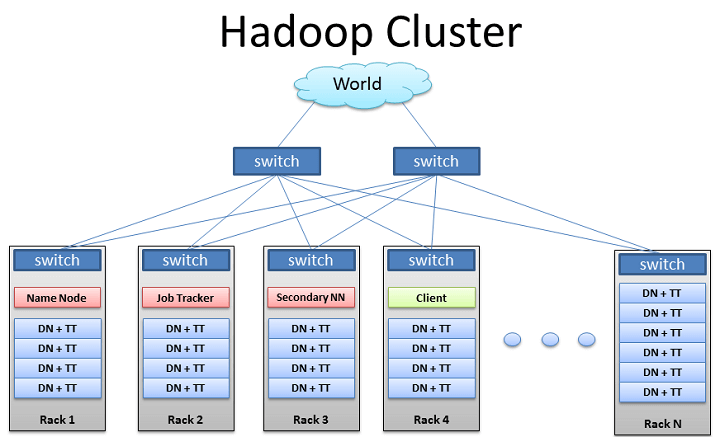
Hadoop on Virtual Machine
Many Hadoop systems don’t only handle the computational stuff but also stores the data and so security becomes a major concern.
So if you are thinking of using Hadoop as a service then you should take care of data security and what can be the best rather than virtualization. Virtualization also adds multi-tenancy offered by YARN and improves system utilization by maximizing resource utilization.
You can use the configuration of a virtual machine like it will have NodeManager/ TaskTracker and a DataNode.
This was all about how to design Hadoop cluster. We hope you got a clear understanding as what all things you should take care while designing a high availability, fault-tolerant Hadoop cluster easily.
Got a question? Shoot below…


Thanks for the detailed article.
I think we should estimate our data size wisely while designing the Hadoop cluster.
This was an awesome guide Ashutosh as usual.
Thanks for the architectural steps.
@Akash
Thanks and glad that you liked it.
I think apart from the current size & incremental size, we should also consider about the infrastructure.
Thank you for this detailed tutorial.
Hello,
Thanks for this tutorial. I agree that we need to consider the future coming data as well while designing Hadoop cluster.
I just wanted to inform you how much we appreciate all you’ve shared to help improve the lives of individuals in this subject material. Through your current articles, we’ve gone through just an ineexeripnced to a pro in the area. It can be truly a honor to your good work. Thanks
Most waited article I found.
Could you please also share about the space calculation of nodes.
Very helpful guide Ashutosh 🙂
Great points you’ve mentioned while designing Hadoop cluster.
Quite helpful guide.
Would love to know more about HA
Great points you have considered here.
Nice post.
Hi,
I think we should also consider the HA point while designing the Hadoop cluster.
I feel that is among the so much significant information for me. And i’m glad studying your article. However should observation on few general issues, The website taste is ideal, the articles is in point of fact excellent D. Just right activity, cheers
[…] the support team, you are refreshing the site and ensuring it is reproducible. Especially, if your system is in the cluster then make sure all the servers associated with it is working […]