In this tutorial, I will be digging around HBase architecture. As we know HBase is a column-oriented NoSQL database and is mainly used to store large data.

HBase is highly beneficial when it comes to the requirements of record level operation. In this HBase architecture explanation guide, we will be discussing everything you should know about HBase architecture.
Introduction to HBase Architecture
HBase architecture mainly consists of three components-
• Client Library
• Master Server
• Region Server
All these HBase components have their own use and requirements which we will see in details later in this HBase architecture explanation guide.
HBase tables are mainly divided into regions and are being served by Region servers. We will discuss these terminologies in detail later in this HBase Architecture tutorial.
Further Regions are divided into Column Families vertically into Stores. And then stores are saved in HDFS files.
So, if you will see the overall picture, it will be like below-

HBase Architecture Components Explanation
Now let’s see the HBase Architecture components in details here.
HBase Master Server
The main role of Master server in HBase architecture is as follows-
• Master server assigns region to region server with the help of Apache Zookeeper
• It is also responsible for load balancing. With that mean, master server will unload the busy servers and assign that region to less occupied servers.
• Responsible for schema changes like HBase table creation, the creation of column families etc.
• Interface for creating, deleting, updating tables
• Monitor all the region servers in the cluster
HBase Regions
HBase tables are divided horizontally into row-key range called “regions” and are managed by region server. So regions are nothing bit the tables that are split horizontally into regions.
Regions are assigned to a node in the cluster called Region server. A single region server can server around 1000 regions.

HBase Region Server
Region server manages regions and runs on HDFS DataNodes. Many times in big data you will find the tables going beyond the configurable limit and in such cases, HBase system automatically splits the table and distributes the load to another Region Server.
The above process is called auto-sharding and is being done automatically in HBase till the time you have servers available in the rack.
Here are some of the important functions of Region server-
• It communicates with the client and handles data-related operation
• Decide the size of the region
• Handle the read and write request for all the regions under it.
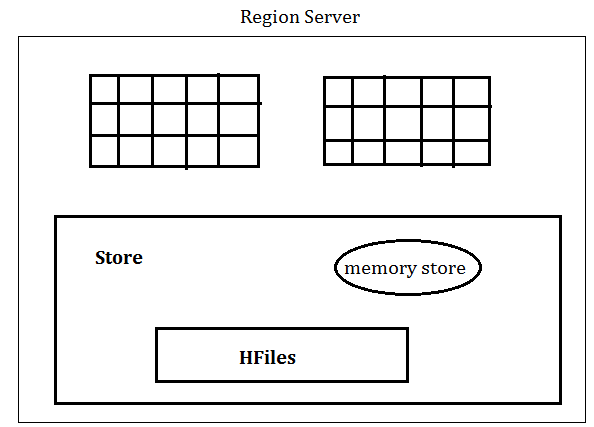
HBase MemStore
HBase memstore is like the cache memory. When we want to write anything to HBase, first it is getting stores in memstore.
Later the data will be sent and saved in Hfiles as blocks and the memstore and memstore will get vanished. There will be one memstore per column family. When the memstore accumulates enough data then the entire data is transferred to Hfiles in HDFS.
HBase Hfiles
As said, whenever any data is being written into HBase, first that gets written into memstore. And when memstore accumulates enough data, the entire sorted key-value set is written into a new Hfiles in HDFS.
The write into HFile is sequential and is very fast.
Zookeeper
HBase uses Zookeeper as a coordinator service to maintain the server state in the cluster. It tells which servers are alive and available and also provides server failure notification.
If you are creating a table in HBase and it is showing you the error like server not enabled etc., check whether Zookeeper is up and running or now.
It also takes care of the network partitions and client communicate with regions through Zookeeper. In Standalone Hadoop and Pseudo-Distributed Hadoop modes, HBase alone will take care of Zookeeper.
Conclusion
This was all about HBase Architecture. HBase is an integral part of the Hadoop ecosystems and used very frequently as a NoSQL database especially when you need to do record level operation.
Share this HBase Architecture post, if you liked it!


Great article! Thanks a lot. I’ve clearly figured out the HBase Architecture.