A neural network is an assembly of simple processing units, nodes, or elements that are interconnected and whose functionality is based on the biological neuron. The network’s processing capability is stored in the strength of interunit connections (weights) obtained by learning (the process of adoption) from a set of training patterns. Neural network systems perform computational tasks that are much faster than conventional systems and this is their objective.
Examples of computational tasks include text to voice translation, zip code recognition, function approximation, and so on. This article provides an in-depth explanation of artificial neural networks.
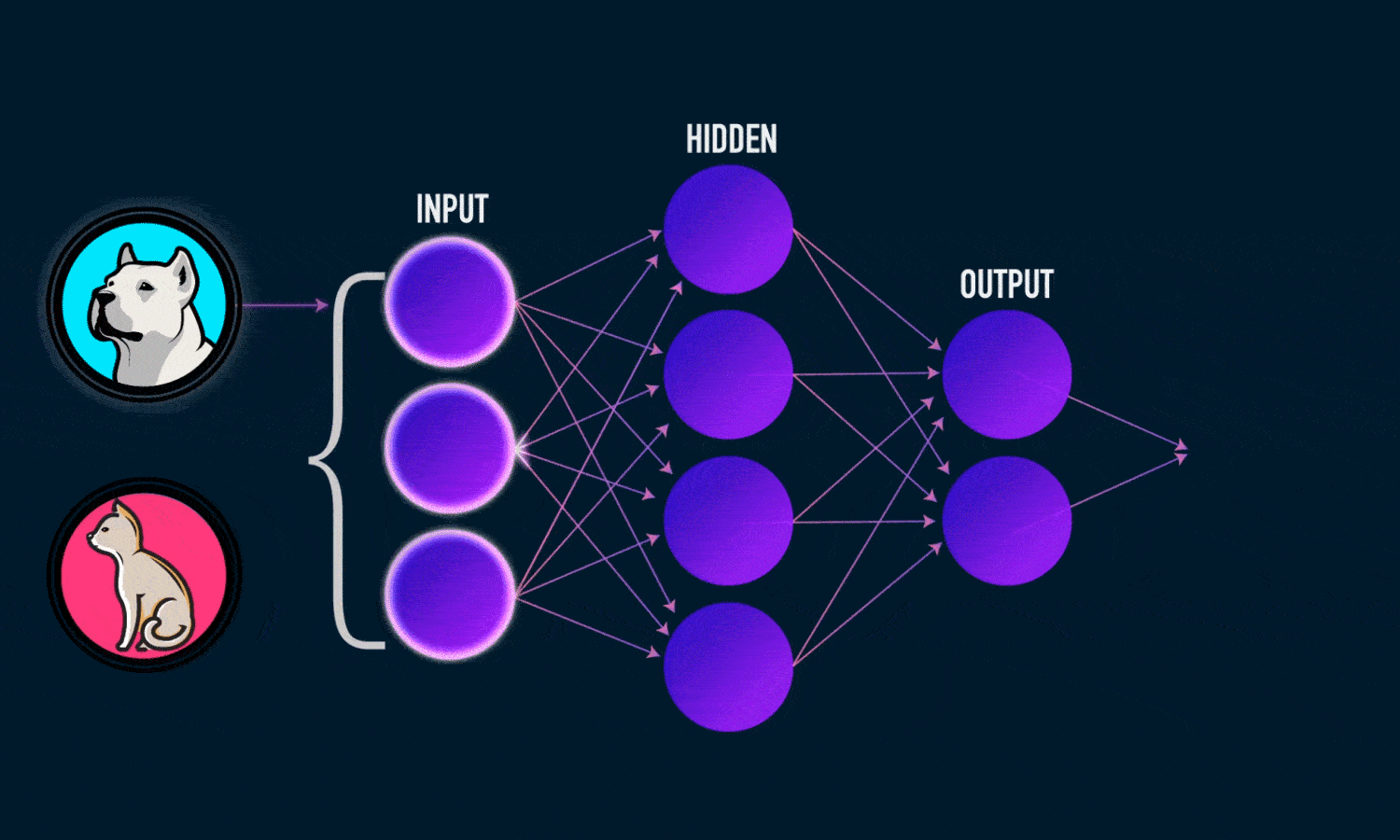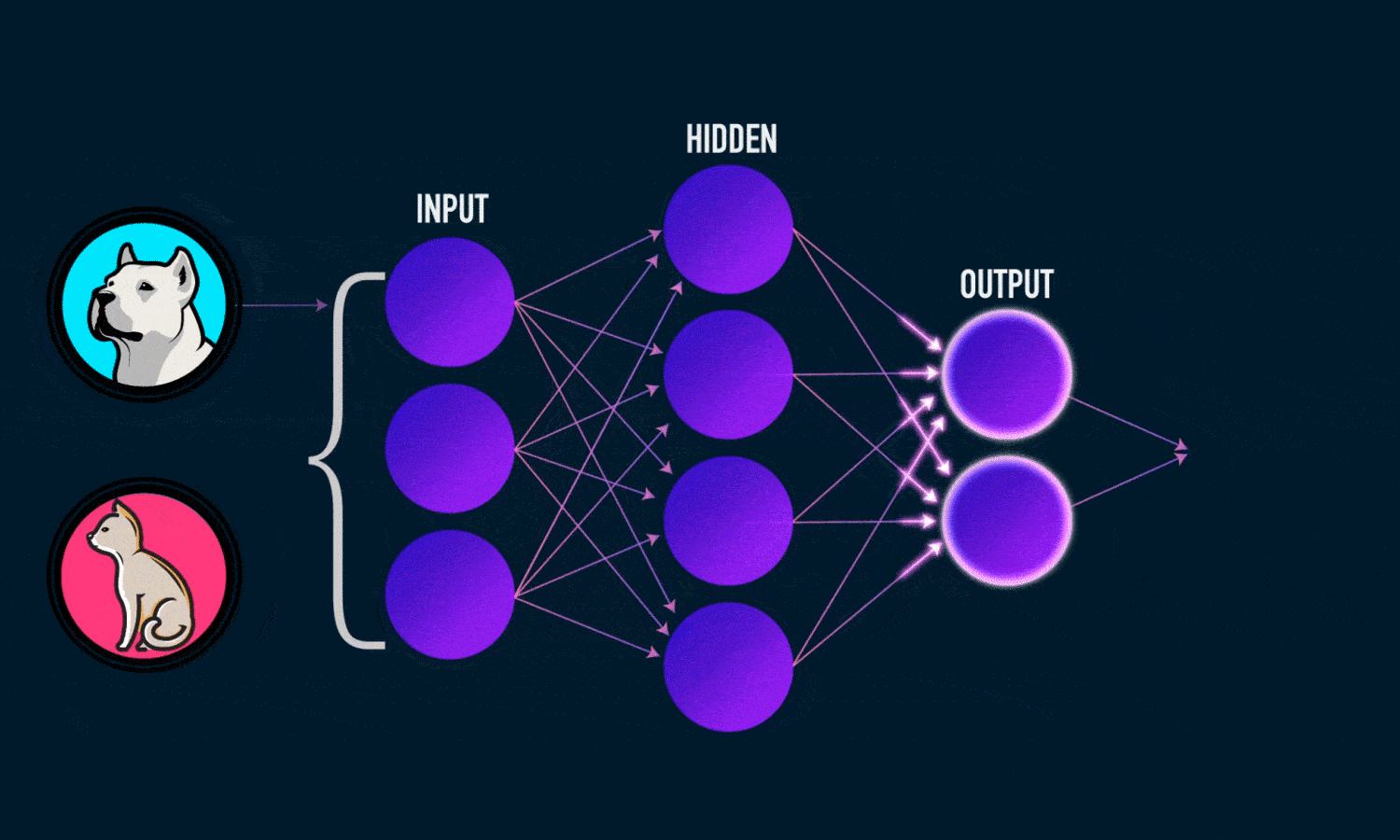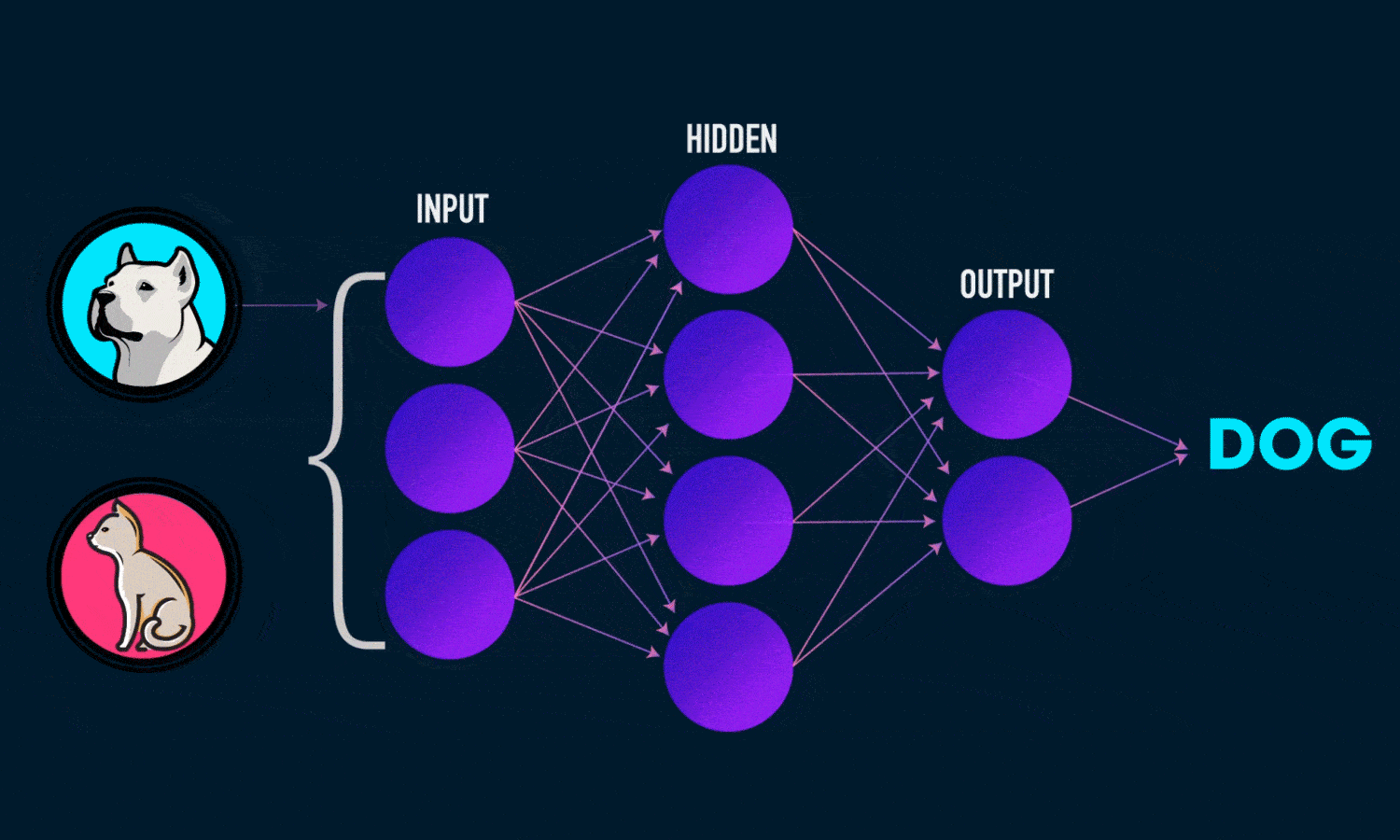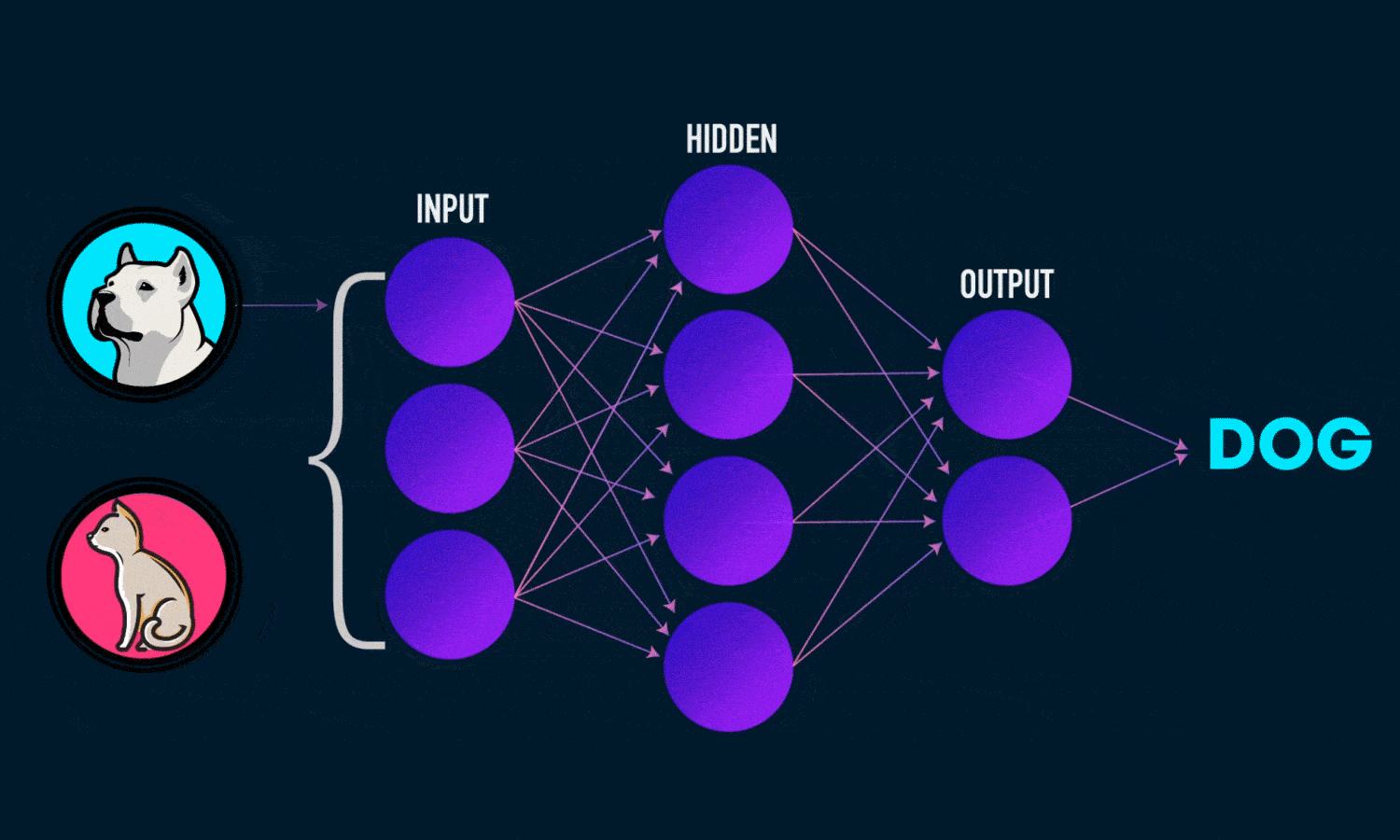
Ai Neural Network
Artificial Neural Network Basics and their Importance
An Artificial Neural Network is defined as a model for processing information that is inspired by the structure and functions of a biological neural network. The information processing system’s novel structure is the key element of this model. It consists of a large number of neurons(interconnected processing elements) working simultaneously to solve specific problems. The ANNs learn by example just like humans.
Artificial neural networks are largely used for data modeling and statistical analysis. The role of ANNs in these techniques is perceived as an alternative to standard cluster analysis or nonlinear regression techniques. Hence, they are generally used in problems that may be formulated in terms of forecasting or classification.
A few examples include textual character recognition, speech and image recognition, and domains of human expertise like financial market indicator prediction, medical diagnosis, geological survey for oil, and so on.
How does an Artificial Neural Network Work?
Neuron is the neural network’s fundamental processing element and encompasses a few general capabilities. A biological neuron basically acquires inputs from various other sources, integrates them and carries out a non-linear operation on the result. Then, it outputs the final result.
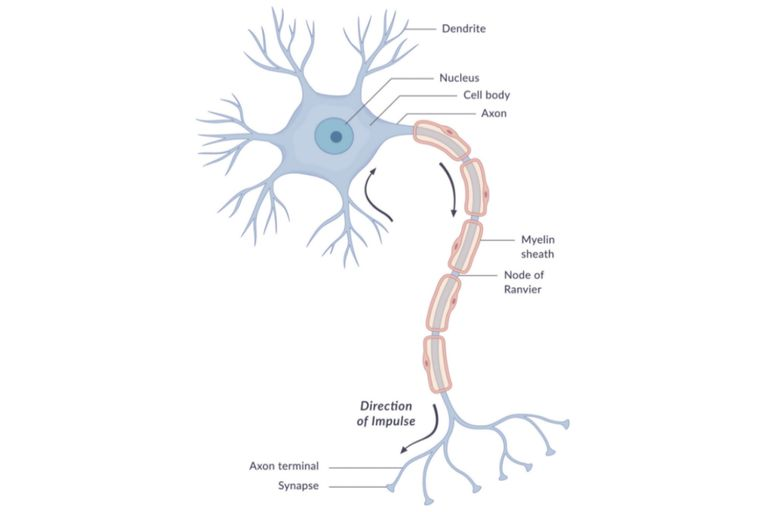
A simple Neuron
There are many variations within humans on this basic neuron type, further complicating their attempts at replicating the thinking process electronically. Yet, the natural neurons basically have four components. They are synapses, axon, soma (cell body), and dendrites. To the cell body, the hair-like extensions are dendrites and they act as input channels. The dendrites obtain their input via other neurons’ synapses.
Over time, the cell body then handles these incoming signals and processes them, thereby converting the value that is processed into an output. The output is then sent to other neurons via the axon and then the synapses.
From the present-day experimental data, it is evident that biological neurons are much more complex than the simple explanation given above. They are more complex than today’s artificial neurons in artificial neural networks. As technology advances and as biology offers a better understanding of neurons, network designers can enhance their systems by building upon the man’s understanding of the biological brain.
The goal of today’s ANNs is not the extravagant recreation of the biological brain. The neural network researchers, on the contrary, are seeking an understanding of the capabilities of nature for which people can develop solutions to problems that haven’t been solved by conventional computing.
To accomplish this, the artificial neurons which are the basic unit of ANNs simulate the four basic functions of biological neurons. The below image shows a fundamental representation of an artificial neuron.
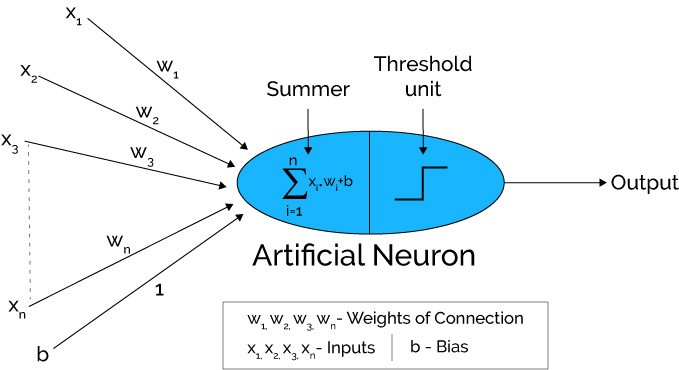
Basic Artificial Neuron
In the above figure, various inputs to the network are represented by x1, x2…xn. These inputs are multiplied by weights of connection which is represented by w1, w2…wn. These products are summed up simply and fed via a transfer function (Threshold Unit) for result generation and then output.
This process contributes to a large-scale physical implementation in a small package. This electronic implementation is still achievable with various other network structures as well which use different transfer and summing functions.
Few applications require binary or black and white answers. These applications include image deciphering of scenes, speech identification, and text recognition.
For these kinds of applications, real-world inputs are turned into discrete values. The discrete values are limited to some known set such as the common 50,000 English words or the ASCII characters. These applications do not always use networks consisting of neurons that simply add up and smooth the inputs due to the limitation of output options.
The binary properties of ANDing and ORing of inputs are used by these networks. These functions, as well as many others, can be integrated into transfer and summation functions of a network.
Other networks work on problems in which the resolution is not one of some known values. These types of networks must be capable of an unlimited number of responses. These types of applications incorporate the intelligence behind robotic movements. The inputs are processed and the outputs which cause some devices to move are created by this intelligence.
The movement of a device can span an unlimited number of precise motions. Indeed, these networks want to smooth their inputs, which occur in interrupted bursts due to limitations of sensors (say 30 times a second for example).
To accomplish that, they receive these inputs and sum the data thereby producing output by using a hyperbolic tangent as the transfer function. The network’s output values are uninterrupted and they satisfy the additional number of real-world interfaces in this manner.
Other applications may just add and compare to a threshold yielding one of two outputs that is possible (a one or a zero).
Architecture of ANNs
The artificial neurons are arranged in a series of layers in an artificial neural network. Basically, an artificial neural network consists of an output layer, a hidden layer, and an input layer.
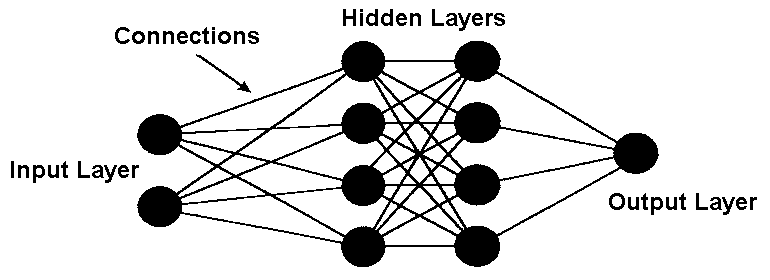
ANN Architecture
The input layer contains those artificial neurons that obtain input from the outside world upon which the network will process, recognize, or learn. The output layer consists of units that respond to the information regarding how it has learned any task.
These units lie between the input and output layers. The hidden layer alters the input into something that the output unit can utilize in some way.
Basically, there are four types of neural network architectures. They are single-layer feedforward architecture, multi-layer feedforward architecture, recurrent or feedback architecture, and mesh architecture.
Single-Layer Feedforward networks consist of one input layer and one output layer (neural layer). The number of outputs will always coincide with the neuron number in networks that belong to this architecture.
The applications include pattern classification and linear filtering. The networks with multi-layer feedforward architecture consist of one or more hidden neural layers. Applications include pattern classification, system identification, and so on.
In networks with feedback architecture, the outputs of neurons are utilized as feedback inputs for other neurons in these networks. They are used for process control and other time-variant systems.
The main features of a network with mesh structures reside in considering the neurons’ spatial arrangement for pattern extraction. This means the neurons’ spatial localization is directly related to the procedure of adjusting their synaptic thresholds and weights.
These are used in problems such as data clustering, system optimization, and so on.
A few popular neural network architectures include multilayer perceptron, radial basis function network, perceptron, LTSM, and recurrent neural networks.
A perceptron is also known as the single-layer perceptron. It is a neural network that contains one output unit and two input units with zero hidden layers. The radial basis function network is similar to the feedforward neural network. The only difference is that the radial basis function is used as an activation function of these neurons. Unlike a single layer perceptron, the multilayer perceptron is used beyond one hidden layer of neurons.
The other name for this network is the deep feedforward neural network. The hidden layer neurons are equipped with self-connections in a recurrent neural network. These networks own a memory. In LTSM (Long/Short Term Memory Network), the memory cell is integrated into hidden layer neurons.
The artificial neural network’s architecture defines how its neurons are placed or arranged in relation to each other. By directing the neurons’ synaptic connections, these arrangements are structured essentially. Within a particular architecture, the topology of a given neural network is defined as distinct structural compositions it can assume.
Most neural networks are fully-connected structures. This implies that each of the hidden neurons is connected entirely to each neuron in the preceding layer(input) and the subsequent(output) layer.
Training Processes
In order to produce the desired output, the neural network learns by adjusting its bias and weights iteratively. Weights and thresholds are also known as free parameters. The neural network is trained first for learning to take place. The defined set of rules with which training is performed is known as the learning algorithm.
The network, during its execution, will thus be able to extricate discriminant features about the system that is being mapped from samples obtained from the system.
There are five types of learning in a neural network. They are online learning, offline learning, reinforcement learning, unsupervised learning, and supervised learning.
In supervised learning, the training data is the input to the network, and the expected output is known weights are adjusted until the output produces the desired value.
In unsupervised learning, the network with a known output is trained with the help of input data. The network categorizes the data at the input and it regulates the weight through the extraction of features in input data.
In reinforcement learning, the network gives feedback whether it is a right or wrong output though the output value is not known. This is semi-supervised learning.
In online learning, the adjustment of the threshold and weight vector is carried out only after each training sample is presented to the network.
In offline learning, the adjustment of the threshold and weight vector is carried out only after the entire training set is presented to the network. This is also known as batch learning.
Learning Datasets
The learning datasets in an ANN include a test set, validation set, and a training set. A test set is a set of examples utilized to assess the fully specified network’s performance or to successfully apply in predicting the output with a known input.
The training set is a set of examples utilized for learning (to fit the network parameters). During the ANNs’ training process, the entire presentation of all the samples that belong to the training set, to adjust the synaptic thresholds and weights, is known as training epoch.
A validation set is a set of examples utilized to tune the network parameters.
Major learning Algorithms
The learning algorithms used in a neural network include backpropagation and gradient descent algorithms. These are a set of steps applied for adjusting the thresholds and weights of its neurons.
A learning algorithm tunes the network so that its outputs are very close to the desired output values. Backpropagation is a prolongation of the delta learning rule based on gradient.
After finding the variance between the target and desired(error), the error is transmitted back towards the input layer from the output layer through the hidden layer. Backpropagation is used for a multilayer neural network!
Gradient Descent is the simplest training algorithm employed in the case of the supervised training model. An error or difference is found in case the actual output differs from the target output.
The gradient descent algorithm transforms the weights of the network such that the error gets minimized. Other learning algorithms include competitive learning, Least Mean Square (LMS) algorithm, Hopfield law, Self-Organizing Kohonen rule, and Hebb rule.
Applications of ANNs
Artificial neural networks are commonly used for clustering, prediction, association, and classification. ANN can be used to determine a particular feature of data and designate them into various categories without any previous knowledge of data.
ANNs are trained to produce outputs that can be expected from a given input (stock market prediction for example). ANNs can be trained to classify a given data set or pattern into a predefined class.
ANNs can be trained to remember a specific pattern so that when the network is presented with a noise pattern, it associates the noise pattern with the closest pattern in the memory or discards it.
ANNs are being applied in many industries including medicine, business, mineral potential mapping, cooperative distributed environments, image processing, geo-technical problems, nanotechnology, aquatic ecology, analysis of thermal transient processes, and so on. If you are in hurry and looking for a quick image editing solution, check online free image editing platform which is a DIY interface and you can do it quickly.
In business, ANNs are used in the areas of credit evaluation and marketing. In medicine, they are used for diagnosing and modeling the cardiovascular system, the implementation of electronic noses, and so on.
Conclusion
This article has given you an in-depth overview of the artificial neural networks. It started with explaining the neural networks and then moved on to ANNs and the reasons for using them.
Later, we dealt with the architecture, training process, and then the applications. Thus, this article gives you a comprehensive overview of ANNs. An artificial neural network carries out a task that a linear program can’t.
ANNs can continue functioning without any problem even when an element of the network fails due to their parallel nature. ANNs learn and they need not be reprogrammed.
ANNs are recognized as statistical tools for data modeling where complex relationships between outputs and inputs are modeled, or patterns are found. They can be performed without any problem and implemented in any application.
About the Author
 This article has been written by Savaram Ravindra. He is working as a Content Lead at Mindmajix. His passion lies in writing articles on different niches which include some of the most innovative and emerging software technologies, digital marketing, businesses, and so on.
This article has been written by Savaram Ravindra. He is working as a Content Lead at Mindmajix. His passion lies in writing articles on different niches which include some of the most innovative and emerging software technologies, digital marketing, businesses, and so on.




Leave a Comment