Earlier our HDFS Tutorial was purely based on Hadoop 1 and when recently I started taking the next Hadoop Developer online training, I realised this has not been updated for so long.
And this post on Hadoop 1 vs Hadoop 2 is in response to that where we are going to see what all have been changed in Hadoop 2 since Hadoop 1. And as we know Hadoop 3 is also out for testing in Beta and so, we are also planning to make a dedicated post on Hadoop 2 vs Hadoop 3 as well.
 But for now, let’s start with Hadoop 1 vs Hadoop 2 and see what all have been changed since the original Hadoop 1.x. Here we write Hadoop 1.x vs Hadoop 2.x as apache foundation keeps on releasing the smaller updates of Hadoop as well with the version name something like 1.1.2 or 2.1 etc.
But for now, let’s start with Hadoop 1 vs Hadoop 2 and see what all have been changed since the original Hadoop 1.x. Here we write Hadoop 1.x vs Hadoop 2.x as apache foundation keeps on releasing the smaller updates of Hadoop as well with the version name something like 1.1.2 or 2.1 etc.
We will categorize this Hadoop 1 vs Hadoop 2 differences based on various factors and will discuss in detail here.
5 Main Differences between Hadoop 1.x and Hadoop 2.x- Hadoop 1 vs Hadoop 2
Here are the major differences between Hadoop 1.0 architecture and Hadoop 2.0 architecture. But before that, there are a couple of major milestones achieved in Hadoop 2.x and those are-
- Hadoop Federation
- High Availability
We will discuss both in detail in the coming section like how high availability has been achieved with Hadoop 2.x which was not available with Hadoop 1.x. But before that, let’s discuss the other differences between Hadoop 1 and Hadoop 2.
Hadoop 1 vs Hadoop 2 Daemons
If you will look into the Hadoop 1.0 daemons, you will find below as the important ones-
- Namenode
- Datanode
- JobTracker
- Tasktracker
But in Hadoop 2, JobTracker and Tasktracker no longer exist. In Hadoop 1, both application management and resource management were done by the MapReduce but with Hadoop 2, resource management has been replaced with a new component called YARN (yet another resource negotiator).
And so, with Hadoop 2, MapReduce is managing application management and YARN is managing the resources.
YARN has introduced two new daemons with Hadoop 2 and those are-
- Resource Manager
- Node Manager
These two new Hadoop 2 daemons have replaced the JobTracker and TaskTracker in Hadoop 1. And the typical Hadoop 2 architecture for daemons will look like the below-
 Here-
Here-
- In YARN, Resource Manager is Master Node
- In MapReduce, NameNode is the Master Node
- Each Resource Manager will interact with Node Manager
Hadoop 1 vs Hadoop 2 Architecture
If you will look into the typical architecture of Hadoop 1 and Hadoop 2, it will look something like below-
 As you can see, in Hadoop 1 architecture only HDFS and MapReduce are there while in Hadoop 2 architecture, another component called YARN has been introduced. So, in Hadoop 1, both application and resource management were taken care by the MapReduce but in Hadoop 2, application management is with MapReduce and resource management is taken care by YARN.
As you can see, in Hadoop 1 architecture only HDFS and MapReduce are there while in Hadoop 2 architecture, another component called YARN has been introduced. So, in Hadoop 1, both application and resource management were taken care by the MapReduce but in Hadoop 2, application management is with MapReduce and resource management is taken care by YARN.
Here in Hadoop 2, NameNode and Resource Manager is the master daemon while DataNode and Node Manager are the slave daemons. Each Node Manager will be associated with each DataNode. And so, a typical Hadoop 2 architecture will look like below.
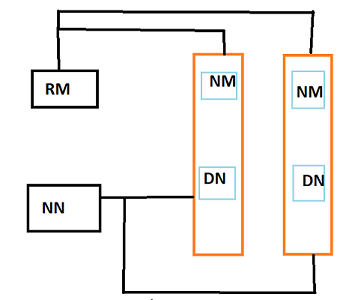 Hadoop Federation
Hadoop Federation
Hadoop Federation is the new concept introduced in the Hadoop version 2 and it basically separates the namespace layer with block storage layer. So, basically NameNode is having metadata and in metadata, we have the following-
- Namespace layer
- Block storage layer
The namespace layer is responsible for the following-
- Info about block or folder
- Info about directory and files
- Responsible for file-level operation- create/modify/delete
- Directory or File Listing
And the block storage layer is mainly divided into following two-
- Block Management and
- Physical Storage
Further block management is responsible for-
- Block Information
- Replication
- Replication Placement
And physical storage is responsible for-
- Stores the blocks
- Provide read & write access
NameNode High Availability
As we discussed earlier while explaining the Hadoop 1 architecture, there was only one namenode and was a single point failover. And so, if in Hadoop 1, if your namenode will fail, your entire cluster will be down.
And this issue has been resolved with Hadoop 2 where we have one active namenode and one standby namenode. And both the active and standby namenode will be in sync every time with auto failover mode. That means, if active means will be down also, passive namenode is always there to take care of the operation. By this way, Hadoop achieves the high availability and single point failover issue has been resolved. Here passive namenode will be an exact replica of active namenode and so, in no time it takes the place of active namenode.
Native Windows Support
Originally, Hadoop was developed to support the UNIX operating system family and linked operating systems. Hadoop 2 has extended its support for native windows support. Hadoop 2 can now cater the extremely popular windows server market.
DataNode caching for faster access
Now the users and applications of the Hadoop ecosystems like Pig, HBase, hive etc. are capable of identifying a different set of files requiring caching. This basically allows the better-read level performance and hence allowing faster access.
HDFS Snapshots
Hadoop 2 offers additional support for file system compatibility. There is a point in time where the system takes the snapshots of complete file systems. This can include the following-
- Protection for user errors
- Reliable backups
- Used for disaster recovery
Wrapping it up!
These were all about Hadoop 1 vs Hadoop 2. Hadoop 2 has definitely overcome most of the issues those were with Hadoop 1. Another difference between Hadoop 1.0 and Hadoop 2.0 is the block size. In Hadoop 1, the default size was 64MB and with Hadoop 2.0. the default block size is 128 MB.
Hadoop 1 vs Hadoop 2
Summary
Hadoop 2 has overcome the majority of issues those were with Hadoop 1 and established as one of the most reliable and stable big data solution.


Leave a Comment